

The Myth of Anonymity
Uncanny ads, correlation, and the longterm future of privacy

An iconic experience of our living on the leading edge of technology is that of the uncanny personalized ad. This is the phenomenon where you are served a targeted ad for something you were recently talking about, thinking about, shopping for (in-person), or otherwise aware of offline, and certain that you left no digital trace of your awareness. It makes you feel a little violated, a little dystopian. I’m pretty confident that almost all of us have had this experience by now. It has been related to me many times by many different people; for instance, it occupied a significant amount of conversation at a recent get-together with my (statistically inclined) coworkers.
“I was at the café with my friend, and we were talking about [product]. And then the next day I saw an ad for [product] on Instagram. Isn’t that creepy? Well, you know, our phones were right there on the table—they must have been listening to our conversation.”
Many of us are familiar with the story of the Golden State Killer (also called the Original Night Stalker), who committed at least 13 murders, 51 rapes, and 120 burglaries between 1974 and 1986—but was only apprehended in 2018. He was anonymous for over 40 years, but finally identified via forensic genealogy. Investigators figured out who his great-great-great-grandparents were by comparing his DNA (samples of which were recovered from crime scenes) to the DNA of individuals in a big database of human genomes (sourced from services like 23andMe). Once they knew that, they could build a big family tree using other public records and then narrow that tree down (using other information they had about him from survivors etc.) to a candidate pool of two suspects.
The first moral of this story is the six degrees of separation idea—you might be anonymous, but you’re connected to other people who aren’t anonymous; you leave a silhouette in the social graph. The second moral of this story is the fact that the thing that dismantled the Golden State Killer’s anonymity wasn’t anything he did—it was progress in information technology. The third moral of this story is that information doesn’t exist in isolation, and everything is correlated: the genealogy database on its own couldn’t do much to identify the Golden State Killer, but combined with a few other data sources it distinguished him from every other person in the US.
There was controversy following the Golden State Killer story, because some people felt that their privacy was violated when the police used their genetic information to identify him (among other reasons; for instance, before the Golden State Killer was successfully identified, forensic genealogy was used to misidentify and accuse an innocent woman). It does feel a bit Philip K. Dick: if you’ve used 23andMe, anyone related to you at the level of third cousins or closer is suddenly going to have a harder time getting away with murder. And I don’t think it will be long before enough people have sent in their spit to genealogy services that everyone in the US is linked at the third cousin level or closer—in fact, it may have already happened.
Similarly, the reason people get worked up when it seems like their phone or smart home device is “listening” to them is it (rightly) feels like a violation of privacy. But this isn’t about the line between what’s okay to track and what’s not. This about the fact that it doesn’t matter, this about the incoherence of the concept of privacy.
Of course your phone is listening to your conversations—but not like that.1 It’s “listening” to your messages on Facebook,2 but I don’t think it’s constantly recording audio. There are at least two simple explanations for the uncanny ad besides your phone listening to your conversation.
The first simple explanation is that the proximity of the conversation and the ad is simply a coincidence—I’m sure this is the explanation in many cases. How many personalized ads do you see on a daily basis? Do you ever notice when an ad is decidedly un-spooky? If you have one or two stories about uncanny ads, it seems like that might not defeat the null hypothesis that they are coincidences—random instances of personalized ads that coincided with relevant conversations simply by chance. There is the improbability principle: “Extremely improbable events are commonplace” (also see the law of truly large numbers), but I’m not even sure if the event is really that improbable. An ad servicer can probably match you up with a pretty narrow range of interests just by knowing your country of residence, approximate age, and gender, for instance. But they probably also have some idea of your online shopping history, YouTube videos you watch, etc. Is it really that surprising if you get an ad for a product and also happen to have a conversation about it?
The second simple explanation is that there actually is some digital signature associated with your conversation and you just aren’t aware of it, for whatever reason. Are you absolutely sure you didn’t google the product after the conversation and then forget about it before you saw the ad? And what caused you and your friend to start talking about the product, anyway? It probably wasn’t an entirely random event. Maybe you were already seeing the personalized ads before the conversation, but you only noticed them subconsciously until after the conversation when they seemed uncanny.
But it doesn’t really matter if either of these benign, simple explanations is true. This is the reality of information—everything is correlated, and so as the world is continuously saturated with information, it becomes easier and easier to make inferences about you.
One of the things that people don’t easily grasp about this topic is the relevance of social networks. The people I’ve talked to about this recognize that social media platforms are recording and consolidating all of your data, but they don’t always recognize that the platforms are also recording data for everyone in your social network.
An ad servicer doesn’t have to know that you are interested in this product to serve you an ad for it (in fact, it doesn’t have to know anything—it’s just going to do its best serve the most effective ads possible). It might be good enough to know that a person you are closely connected to is interested in this product. My personal anecdote here is that I constantly use ad blockers, so I don’t see very many personalized ads, but my fiancée does—and she sees ads targeted at me. She will ask me, “Were you shopping on [website].com recently?” And I’ll say, “Yep, just yesterday,” or whatever. And this isn’t particularly spooky. My fiancée and I are very, very close together in the social graph, and there are plenty of digital signatures for this: we are constantly in the same location, we are connected on every single social media platform, we message each other, etc. So an ad servicer probably sees it as a complete win to serve my fiancée an ad that is actually targeted at me… but it’s not even that anthropomorphic, right? There’s not a person sitting behind the ads making a decision about which one to show you. There’s just a bunch of data going into an algorithm. That algorithm is probably leveraging all sorts of clever things you wouldn’t immediately guess, like the patterns and interests of people in your social network.
The point of this is that even if you worked really hard to avoid leaving digital signatures (using incognito mode, for example), you won’t always thwart the targeted ads. Certain information about you can be determined whether you offer it to the internet or not. Information (about yourself or otherwise) isn’t really something that you can just choose to upload or not upload, and privacy isn’t as simple as the “accept all cookies” button. Information is something that exists, and our access to it is only a matter of our trace on it. Sometimes that trace is a direct digital signature, like your voluntarily accepting cookies, and other times that trace is a silhouette, like the silhouette you leave in the genealogy databases. As information technology moves forward, the density of digital signatures increases, and so does the frequency and resolution of the silhouettes.
When you work with data, especially data describing individual people, and especially if you work with people in Europe, you have to be familiar with anonymization. This is the practice of removing identifiers (like names and email addresses) from datasets. Data anonymization is mandatory to be “GDPR-compliant.” This is the sort of thing that comes up in communications with clients (“We only work with anonymized data,” etc.), which is to say it affects the bottom line of a lot of IT-type businesses in a very big way. The idea behind anonymization is that the person described by a datum is no longer identifiable, so that e.g. the third-party people working with the data (such as myself) don’t know who the data describe, but more importantly so that if there is any kind of data leak, any other (malicious) third parties don’t know who the data describe. This makes everybody involved (especially the lawyers) feel a little bit better about the passing around and usage of data.
The problem is that, because everything is correlated, there’s such a thing as de-anonymization, or re-identification, which is the practice of making the individuals in unidentified data identifiable again by combining other data sources. Which means there’s a big problem lurking in all of this privacy policy. For instance, to achieve anonymization under GDPR (to be GDPR-compliant), it must be “impossible” to re-identify the data. But this is an impossible standard.
In Gwern’s outstanding piece about the information theory of Death Note, he has an aside about this, giving a bunch of examples for ways you could be identified. He also links a paper about de-anonymization of social networks, and quotes the authors:
We do not believe that there exists a technical solution to the problem of anonymity in social networks.
For an illustrating example, consider the US Census. In 1997, Latanya Sweeney demonstrated using the 1990 census data that you can determine the identity of someone if you know their date of birth, zip code, and gender.
Differential privacy describes the practice of anonymizing a dataset more strongly—going beyond simple anonymization (removing identifying information) and ensuring that de-anonymization is impossible.3 Great! It sounds like that's answer to the problem of de-anonymization; there’s nothing wrong with GDPR and other regulations; we just need to get better at privacy. It’s an extremely hard problem, sure, but it’s our responsibility to solve it.
The 2020 Census apparently came with some new differential privacy techniques, and their handbook on the subject actually contains a pretty good layperson explanation of the practice (see page 6). This figure is included:
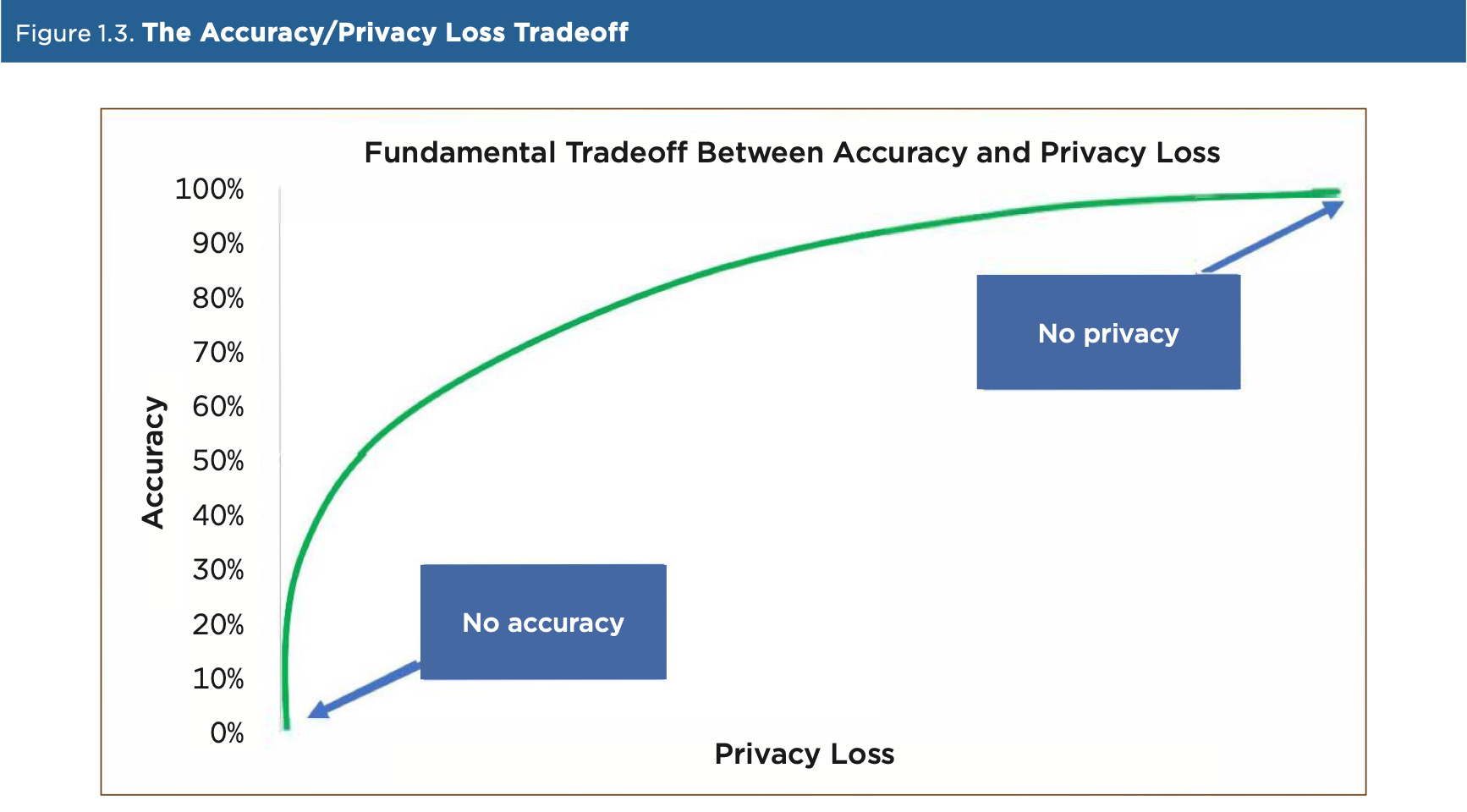
This illustrates the tension of differential privacy. They use the word “accuracy” but you could also use the world “interesting” or “valuable” or “useful.” As you add noise to data, it becomes more anonymous, but it also reduces the amount of useful information in the data. A paper from the UCLA Law Review makes it plain: “Data can be either useful or perfectly anonymous but never both.” At perfect anonymity, you have white noise. At perfectly resolved and rich data, you have a privacy advocate’s worst nightmare. How will we draw a line on this curve and say “All datasets must be at least this anonymous and if you need better information than that, too bad”? And even if we could agree on a line like that, how could we ever be sure that a dataset was on the right side of it?
Two trends here seem certain to continue into the longterm future:
The amount of information that is stored and shared will continue to increase.
We will continue to improve our ability to access and harness information, as technologies like databases, ML, and easy-to-use data analysis tools improve, and fluency in these technologies becomes increasingly common (do you think programming won’t be required for all high schoolers within 20 years? do you think artificial intelligence fluency won’t be required for all high schoolers within 100 years?)
In the limit, these trends together take us to a future where there is no such thing as privacy.
I’m concerned that, in the nearer term, our failure to recognize the impossibleness of ideal anonymity will lead to real adverse effects, for instance a lack of valuable datasets for research. With that being said, I don’t really think there’s anything wrong with privacy regulations and anonymization practices in the present day. The type of anonymization I have to do is easy, and the type of anonymized data that I have to work with are still very interesting and useful. Maybe anonymization efforts are even helping to thwart potential bad actors. But if they are, that’s only because the bad actors aren’t sufficiently capable of bad acts, and they’re acting in an underdeveloped information landscape.
I do think there are problems with the the language used to describe requirements for privacy and anonymization, which could cause some serious issues in the future, but I’m sure that’s a bridge we’ll cross. How, exactly, we’ll cross it is another story entirely, because the concept of privacy is certainly going to collapse—privacy is something that only exists in a relatively nascent informational society.
Of course, I can’t be certain of this. It’s absolutely possible that our phones are literally listening and streaming conversations to personalization algorithms, but the point is that I don’t think the uncanny ads are necessarily evidence of this.
My fiancée (then girlfriend) started getting ads for engagement rings after I sent some links to her maid of honor (then only sister-in-law) on Facebook Messenger. We all have stories like this. It feels dystopian, but not uncanny because I know exactly why she started getting the ads.
This is an oversimplification of differential privacy. The real definition would be more like the practice of modifying a dataset such that any statistical analysis of the dataset will have the same results whether or not any individual subject in the data is included. But even this is selling it short.
wonderful article and a wonderful read. you’re a great writer!
'silhouette in the social graph' is a particularly elegant way of putting this, both to describe the rather fantastic (somewhat dystopian, yet benevolent) instance of the golden state killer and also the more pedestrian uncanny ad phenomena.
also very interesting point about the associations and connective work algorithms do that wouldn't be obvious associations to us. i think this is a really important missed aspect of all many tech and ethics discussions because it is hard to understand functionally, let alone talk about.